 PlaneText is a framework for assisting you to apply any NLP tools you like to target real-world documents containing structured text. Currently, a tool is being developed for converting XML-tagged text into plain text sequences which can be directly input to NLP tools.
PlaneText is a framework for assisting you to apply any NLP tools you like to target real-world documents containing structured text. Currently, a tool is being developed for converting XML-tagged text into plain text sequences which can be directly input to NLP tools.
Downloadable tool package will be released in SeptemberObtober, 2014.
You can try an online demo here.

Basic concept: converting XML document into plain text based on tag classification
Real-world documents do not simply consist of sentence sequences, but are “structured”. In some cases, they are sectioned, chaptered or footnoted, etc. In some cases, expressions which cannot be represented by normal characters, such as mathematical expressions, figures, or tables, are introduced into sentences. In some cases, sizes or colors of certain characters are changed. In other cases, some information which is not displayed but used for managing documents is embedded.
M ost of natural language processing (NLP) tools, on the other hand, assume that input text consists of sequential sentneces, and therefore a user of the tools has to convert every target document into text sequences which can be input to the tools, which is very bothersome and delicate labor. Some users may give up using the tools, or other users may forcibly input such structured text to the tools and spoil the potential of the tools.
ost of natural language processing (NLP) tools, on the other hand, assume that input text consists of sequential sentneces, and therefore a user of the tools has to convert every target document into text sequences which can be input to the tools, which is very bothersome and delicate labor. Some users may give up using the tools, or other users may forcibly input such structured text to the tools and spoil the potential of the tools.
PlaneText is develeped for removing such barriers and problems that occur when people try to apply NLP tools to real-world documents.
 The current version assumes that text is structured by XML tags, and provide the framework for converting structured text into plain text sequences which can be input to NLP tools, according to classification of observed tags into four types: Independent, Decoration, Object, and Meta-info tags. Although human labor is still required for tag classification, PlaneText eases the labor both by an efficient classification procedure and by two types of interfaces for the procedure: GUI-based and command line-based.
The current version assumes that text is structured by XML tags, and provide the framework for converting structured text into plain text sequences which can be input to NLP tools, according to classification of observed tags into four types: Independent, Decoration, Object, and Meta-info tags. Although human labor is still required for tag classification, PlaneText eases the labor both by an efficient classification procedure and by two types of interfaces for the procedure: GUI-based and command line-based.
Four functional types of XML tags
PlaneText assumes that structurization of text is represented by XML tags, and classifies XML tags into four functional types of structurization.
- Independent: regard a tagged region as separate from surrounding text
- Decoration: change the displayed style of tagged region
- Object: introduce some non-natural-language structure into text
- Meta-info: insert some information on text which is not displayed
Take scientific papers for example. Each section, title, footnote or etc. is completed text while the region can be embedded within another sentence. In order to properly separate such regions from surrounding text, “Independent” tags are utilized.
Changing the size, color, font of characters in some regions or making some regions link to other locations, on the other hand, does not mean separation of sentences but just decorate or emphasize the target regions. The tags bringing such functions, that is, “Decoration” tags, can be therefore ignorable. (Such decoration or emphasis can actually suggest some word separation etc. which can be useful information for NLP tools. We are planning to utilize the information in our furture update.)
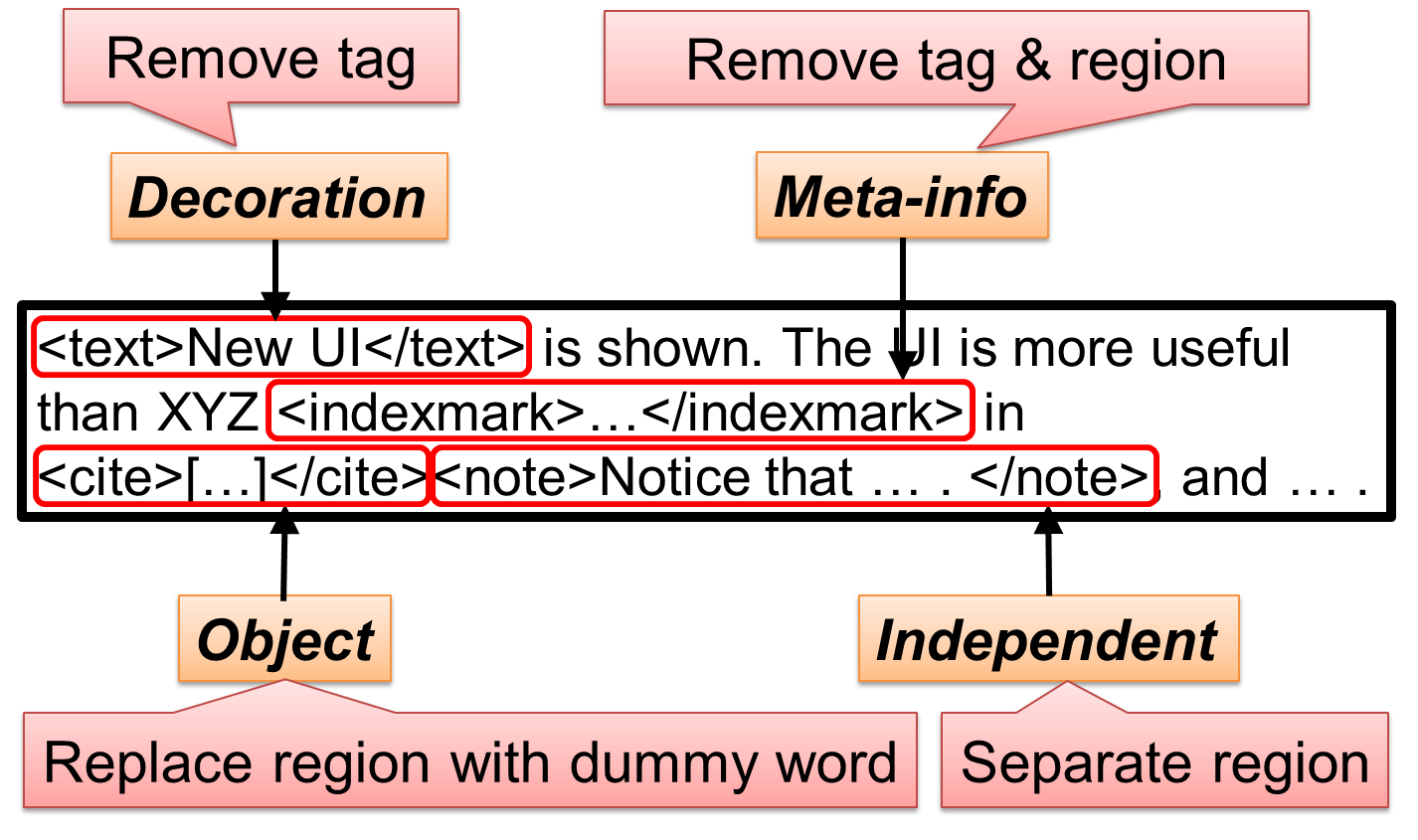 Mathematical expressions, figures, tables, itemization, etc. have some structures consisting not of simple characters but of special structures, symbols, images etc. and therefore cannot be analyzed by NLP tools. In PlaneText, such structures are called “Object” and the tags introducing Objects are called “Object” tags. (There are actually text within Object tags, which will be considered in our future update.)
Mathematical expressions, figures, tables, itemization, etc. have some structures consisting not of simple characters but of special structures, symbols, images etc. and therefore cannot be analyzed by NLP tools. In PlaneText, such structures are called “Object” and the tags introducing Objects are called “Object” tags. (There are actually text within Object tags, which will be considered in our future update.)
The above three types of tags represent elements which are displayed while text sometimes contains not-displayed elements which give bookmarks for making index, adding information for managing documents, etc. The tags representing such regions are called “Meta-info” tags.
In PlaneText, according to classification of tags in the documents into the above four types, structurized documents are converted into plain text sequences which can be directly input to NLP tools, by “extracting each of text regions enclosed by Independent tags”, “removing Decoration tags”, “replacing the regions enclosed by Object tags with dummy words”, and “removing the regions enclosed by Meta-info tags”. 
In many cases, each organization or publisher issues or holds documents in a certain style of tag fomat, and it is therefore possible to process a large amount of documents in the same format once classification of tags for the format is given.
Reflect user’s intention into tag classification
A document can consist of various textual regions separated by XML tags, and which part of the document to analyze using NLP tools — body text with titles excluded, publications in bibliography, or etc. — can accordingly vary among users.
In PlaneText, different demands by users can be reflected by changing the classification of tags. You can ignore titles in your NLP analysis by classifying the tags enclosing titles into Meta-info tags, or you can focus only on a publication list by classifying any tags other than the ones which enclose bibliography sections into Meta-info tags.
PlaneText thus leaves the final decision on tag classification to a user, while it introduces the procedure which decreases the user’s labor of tag classification by suggesting a minimal number of tags to classify. In our experiments, for each of several formats of documents, the documents can be converted into text sequences which can be input to NLP tools by classifying only one-fifth of tags in the documents [1].
 PlaneText は「構造化されたテキストを含む実世界の文書を、手持ちの自然言語処理 (NLP) ツールで解析したい」という目的を支援するための枠組です。現在のバージョンでは、XML タグで囲まれたテキストを NLP ツールに直接入力できるような文に変換できるよう、ツールの開発を進めております。
PlaneText は「構造化されたテキストを含む実世界の文書を、手持ちの自然言語処理 (NLP) ツールで解析したい」という目的を支援するための枠組です。現在のバージョンでは、XML タグで囲まれたテキストを NLP ツールに直接入力できるような文に変換できるよう、ツールの開発を進めております。
本枠組のダウンロードパッケージの公開は、2014年の9月10月を予定しております。
こちらで GUI 版のオンラインデモを試すことができます。使い方も併せてご参照ください。

基本コンセプト:タグ分類に基づく XML 文書の平文テキスト化
世の中の文書は、単純に文が一列に連続して並べられているだけではなく、「構造化」が行われています。例えば、段落や章立て・脚注などで区分けがされていたり、数式や図表等の通常文字列のみでは表しきれない表現が導入されていたり、ある部分だけ文字の大きさや色が変更されていたり、あるいは、文としては捉えられないような管理のためだけの情報が埋め込まれていたり--。
 自然言語処理 (NLP) のツールは、その多くが文が一列に連続して並べられていることを前提にしているため、このような様々な構造化については、ツールを使う人間が考慮して、その都度、ツールに入力できるような形に文書を変換してやる必要があります。これは非常に煩わしく、また繊細な作業となります。人によっては使うのを断念するかも知れませんし、あるいは、無理矢理ツールに入力することで、折角の NLP のツールが持つポテンシャルを最大限に引き出せない、ということもあるでしょう。
自然言語処理 (NLP) のツールは、その多くが文が一列に連続して並べられていることを前提にしているため、このような様々な構造化については、ツールを使う人間が考慮して、その都度、ツールに入力できるような形に文書を変換してやる必要があります。これは非常に煩わしく、また繊細な作業となります。人によっては使うのを断念するかも知れませんし、あるいは、無理矢理ツールに入力することで、折角の NLP のツールが持つポテンシャルを最大限に引き出せない、ということもあるでしょう。
 PlaneText は、NLP ツールを実文書に適用する際に生じるこのような障壁・問題を解決するために開発されています。
PlaneText は、NLP ツールを実文書に適用する際に生じるこのような障壁・問題を解決するために開発されています。
現在のバージョンでは、テキストの構造化が XML のタグによって表されているものという想定の下、このタグをその機能に基づいて4種類(独立・装飾・実体・非表示)に分類すれば、その分類に基づいて、構造化されたテキストを、NLP のツールに入力できるような平文テキストの列に自動変換してくれる仕組みを実装しています。また、その分類作業も、コマンドライン および Web ブラウザを介した GUI ツール での2通りの方法による支援と、効率的な分類手続きの導入により、利用者の負担を下げるよう工夫されています。
機能に基づくXML タグの4分類
PlaneText ではテキストの構造化が XML のタグによって表されているものという想定の下、その機能を以下の4つに分類します。
- 独立(Independent): タグで囲まれた部分を、周囲とは区切られた文(文章)として見なす
- 装飾(Decoration): タグで囲まれた部分の表示スタイルを変化させる
- 実体(Object): 自然言語ではない何らかの構造を文章中に導入する
- 非表示(Meta-info): 実際にはディスプレイには表示されない、テキストに関する何らかの情報を挿入する
論文を例にとると、各セクションやタイトル・脚注は、それぞれで完結した文章となっていますが、それを表すタグで囲まれていなければ、例えば、脚注文は本文中に突然挿入されるので、タグを無視すると文が文の中に不自然に埋め込まれてしまいます。このような、周囲と区切られるべき領域を表す(囲む)タグを独立タグと呼びます。
一方で、ある領域の文字のサイズ・色・フォント等を変更したり、あるテキスト部分にリンクをはったりするのは、文としての区切りではなく、単純にその部分を装飾・強調しているものなので、タグを無視したとしても不自然な文章にはなりません。(実際には、その「装飾・強調された」ということが、単語の区切りを表すなど、NLP における有用な情報とはなり得ますが、その情報の利用については今後のバージョンで検討予定です。)このようなタグを装飾タグと呼びます。
 数式や図表・箇条書きなどについては、テキスト中に現れるものの、その構造は、単純な文字列ではなく、特殊な構造や記号、あるいはイメージを伴うものとなっており、 NLP ツールでは解析が意図されてはいないものになっています。このような構造を実体(Object)と呼び、この実体を導入するタグを実体タグと呼びます。(実体タグの中にもテキストがありますが、これらの解析については今後対応を検討予定です。)
数式や図表・箇条書きなどについては、テキスト中に現れるものの、その構造は、単純な文字列ではなく、特殊な構造や記号、あるいはイメージを伴うものとなっており、 NLP ツールでは解析が意図されてはいないものになっています。このような構造を実体(Object)と呼び、この実体を導入するタグを実体タグと呼びます。(実体タグの中にもテキストがありますが、これらの解析については今後対応を検討予定です。)
以上3つのタグに関しては、ディスプレイ上に表示される要素でしたが、それ以外にも、索引を作るためにブックマークをつけたり、文書を管理するための情報をつけるなど、実際には表示されないような要素がタグで表されることがあります。これを非表示タグと呼んでいます。
 以上の4種のタグを踏まえ、PlaneText では、対象文書中で使用されているタグをこれらの4種に分類すると、「独立タグで囲まれたテキスト部分毎に切り出し」、「装飾タグを除去し」、「実体タグで囲まれた領域を代替のダミー文字列で置換し」、「非表示タグで囲まれた領域を除去する」という操作を行うことで、構造化された文書を、NLP のツールで処理せずに解析できるような平文のテキスト列へと変換します。
以上の4種のタグを踏まえ、PlaneText では、対象文書中で使用されているタグをこれらの4種に分類すると、「独立タグで囲まれたテキスト部分毎に切り出し」、「装飾タグを除去し」、「実体タグで囲まれた領域を代替のダミー文字列で置換し」、「非表示タグで囲まれた領域を除去する」という操作を行うことで、構造化された文書を、NLP のツールで処理せずに解析できるような平文のテキスト列へと変換します。
文書を発行・管理している組織や出版社によっては、このようなタグの仕様が決まっていますので、同じ仕様の文書群であれば、一度のタグ分類で多くの文書を一括処理することが可能になります。
利用者の意図を分類に反映させる
文書は XML タグによって役割を定められた様々な領域から構成されており、そのうちのどの部分を NLP ツールで解析するのか--タイトルを含まない本文だけを解析するのか、あるいは参考文献の論文リストだけに注目するのか、など--は利用者によって異なります。
PlaneText では、このような意図の差に関しては、利用者がタグの分類を変えることで対応できるようにしています。もし、タイトルを解析から除外したいのであれば、タイトル部分を表す(囲む)タグを「非表示タグ」に分類すれば、その部分は出力からは除外されますし、逆に、参考文献だけ解析したいのであれば、その部分のタグ以外を全て「非表示タグ」に分類すれば良いことになります。
そのため、PlaneText においては、タグの分類の最終的な判断を利用者に委ねていますが、その分類の負担をできる限り抑えるべく、変換に最低限必要なタグのみを分類できるような仕組みを導入しています。これにより、実験に用いた複数の文書群では、文書中の使用タグの5分の1以下のタグを分類するのみで、NLP ツールで解析できるテキスト列への変換ができることを確認しております [1-2]。